背景
今天来看一下这篇发表在ICCV2023的论文《LightGlue: Local Feature Matching at Light Speed》。【论文下载】 【开源代码】
搞机器人SLAM或者三维重建,都会涉及到SfM(structure-from-motion)问题。该问题的标准流程参考colmap开源SfM框架如下所示:

相机从不同角度拍摄同一个地点,然后从两张图像中通过图像匹配,计算相机在两个拍摄角度的相对位置姿态,进一步恢复出拍摄地点的3D坐标,即重建。其中一个核心的问题在于第二个框框里的“Correspondence Search”,也就是图像匹配问题,主要分为两步:特征提取和特征匹配。
在colmap中图像匹配基于SIFT特征,是David Lowe老爷子1999年发明的,纯手工打造,也是属于实验科学。具体提取流程这里按下不表,有兴趣的同学可以参考这篇中文博客SIFT 特征。SIFT特征是一个128维的特征向量,匹配时以两个特征向量的欧式距离作为相似度的度量。当然匹配时,也需要进行最近邻(NN)寻找,以找到待匹配的特征点。SIFT特征在计算机视觉中举足轻重,David Lowe老爷子因此在2015年获得了PAMI Distinguished Researcher Award。这个奖ICCV两年颁一次,一次只有1-2个人获奖。值得一提的是,2015年和老爷子一起获奖的另一个人是Yann LeCun ,有点新旧交替的意味了。
不过,目前看SIFT这类传统手工方法的提取&匹配方法也要被深度学习方法替代了。主要也是因为VR/AR领域应用对性能的要求恰好与深度学习尤其是Transformer方法的进步match了。先是MagicLeap在2018年发布SuperPoint特征提取方法,ETH Zurich联合Magic Leap在2020年发布SuperGlue特征匹配方法,再到今年1月份ETH Zurich联合微软MR&AI Lab发布SuperGlue的升级版本LightGlue。我们现在看谷歌在Kaggle的图像匹配挑战赛IMC2023,拔得头筹的方案基本都有深度学习特征点提取和匹配的影子。
相比于传统方法,基于深度学习的图像匹配方法具备一些优势,如对于弱纹理、光照或视角变化引起的纹理变化都具备比较好的鲁棒性。
因此,这篇文章从工程落地的角度,把LightGlue的原理和代码结合起来,跟大家过一遍,有一些原理性的东西会略过,请自行查看文献或者参考其他博客。 本人属于SLAM传统流派,对深度学习方法也在学习中,如有错误请指出,谢谢!
整体架构
LightGlue模型衍生自当前火热的Transformer模型,整体架构如下所示:
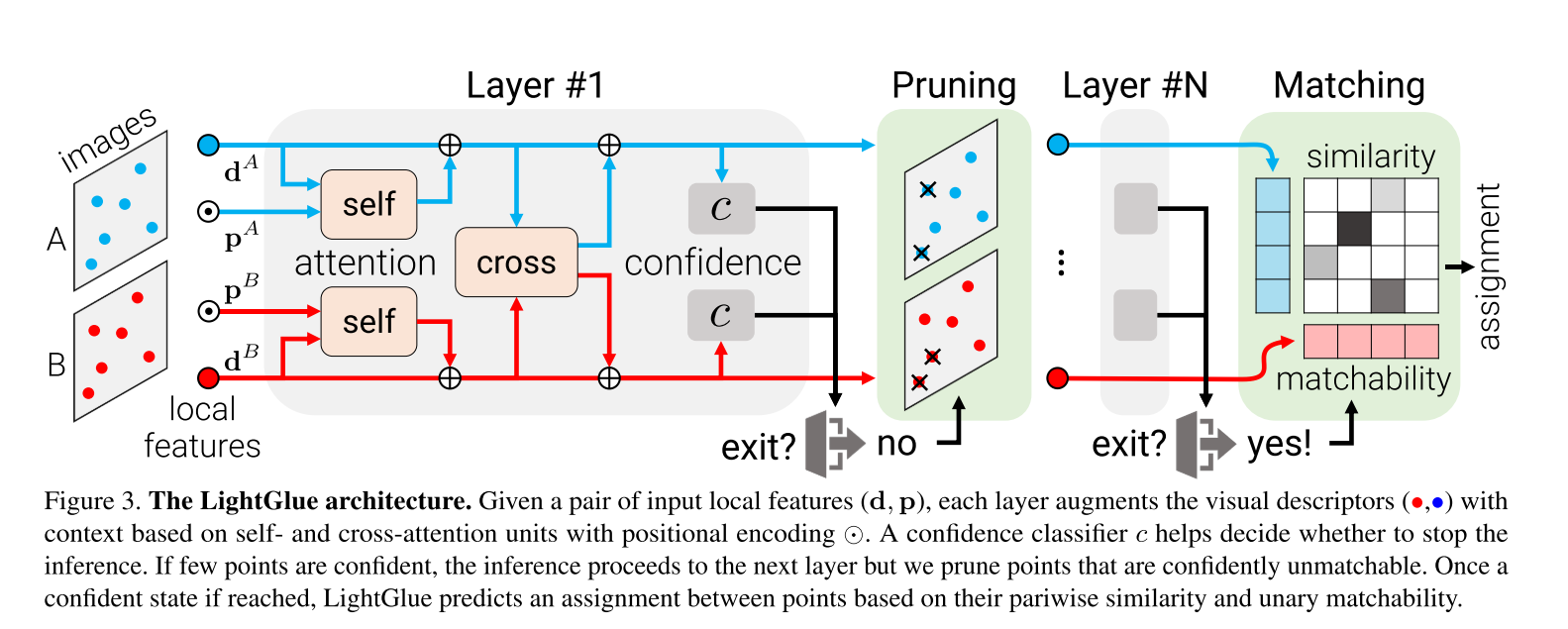 模型包含层self-attention&cross-attention网络,每层网络后都会做一次判断,决定是否继续往下推理,同时会进行特征点裁剪。最终通过一个轻量级的检测头来计算匹配矩阵。
模型包含层self-attention&cross-attention网络,每层网络后都会做一次判断,决定是否继续往下推理,同时会进行特征点裁剪。最终通过一个轻量级的检测头来计算匹配矩阵。
问题定义:给定从图像和中提取的两组特征点,每个特征点由归一化的2D坐标 和视觉描述子 组成。图像有个特征点,用表示。类似的,图像有个特征点,用表示。对图像的特征点都关联一个状态,初始化为描述子,后续由网络层更新。
特征匹配的任务是预测对应的匹配矩阵,这对应寻找一个软部分分配矩阵(soft partial assignment matrix) 。表示图的第个特征点匹配上图的第个特征点的可能性。“软分配”的意思指的是矩阵元素不仅仅是绝对的0或1。理论上的任意行之和或任意列之和等于1。但实际情况,可能由于视场角变化/遮挡/光照等因素,图的特征点在图没有对应的匹配点,对应的和就不等于1。软部分分配矩阵定义如下:
LightGlue的目标是给定两组局部特征点,通过神经网络预测软部分分配矩阵。
DEMO代码
以下是调用LightGlue进行特征匹配的代码实例,属于非常标准的特征提取和特征匹配代码流程:
from lightglue import LightGlue, SuperPoint, DISK, SIFT, ALIKED
from lightglue.utils import load_image, rbd
# SuperPoint+LightGlue
extractor = SuperPoint(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='superpoint').eval().cuda() # load the matcher
# or DISK+LightGlue, ALIKED+LightGlue or SIFT+LightGlue
extractor = DISK(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='disk').eval().cuda() # load the matcher
# load each image as a torch.Tensor on GPU with shape (3,H,W), normalized in [0,1]
image0 = load_image('path/to/image_0.jpg').cuda()
image1 = load_image('path/to/image_1.jpg').cuda()
# extract local features
feats0 = extractor.extract(image0) # auto-resize the image, disable with resize=None
feats1 = extractor.extract(image1)
# match the features
matches01 = matcher({'image0': feats0, 'image1': feats1})
feats0, feats1, matches01 = [rbd(x) for x in [feats0, feats1, matches01]] # remove batch dimension
matches = matches01['matches'] # indices with shape (K,2)
points0 = feats0['keypoints'][matches[..., 0]] # coordinates in image #0, shape (K,2)
points1 = feats1['keypoints'][matches[..., 1]] # coordinates in image #1, shape (K,2)代码流程
我们直接看核心代码LightGlue中的forward函数,给出对应的处理流程。
首先明确好输入输出:
def forward(self, data: dict) -> dict:
"""
Match keypoints and descriptors between two images
尺寸解释:B -> batch size, M -> 图A特征点数, N -> 图B特征点数, D -> 特征点状态的维度, C -> 图像通道数, H -> 图像高, W -> 图像宽
Input (dict):
image0: dict
keypoints: [B x M x 2]
descriptors: [B x M x D]
image: [B x C x H x W] or image_size: [B x 2]
image1: dict
keypoints: [B x N x 2]
descriptors: [B x N x D]
image: [B x C x H x W] or image_size: [B x 2]
Output (dict):
matches0: [B x M]
matching_scores0: [B x M]
prune0: [B x M]
matches1: [B x N]
matching_scores1: [B x N]
prune1: [B x N]
matches: List[[Si x 2]]
scores: List[[Si]]
stop: i + 1
"""数据处理流程主要是:
-
kpts0 = normalize_keypoints(kpts0, size0).clone() kpts1 = normalize_keypoints(kpts1, size1).clone() -
运行Transformer主干网络,最核心部分:
for i in range(self.conf.n_layers): desc0, desc1 = self.transformers[i]( desc0, desc1, encoding0, encoding1, mask0=mask0, mask1=mask1 ) -
深度动态调整。每层网络后,判断是否提前结束推理:
if do_early_stop: token0, token1 = self.token_confidence[i](desc0, desc1) if self.check_if_stop(token0[..., :m, :], token1[..., :n, :], i, m + n): break -
宽度动态调整。每层网络后,清除特征点:
if do_point_pruning and desc0.shape[-2] > pruning_th: scores0 = self.log_assignment[i].get_matchability(desc0) prunemask0 = self.get_pruning_mask(token0, scores0, i) keep0 = torch.where(prunemask0)[1] ind0 = ind0.index_select(1, keep0) desc0 = desc0.index_select(1, keep0) encoding0 = encoding0.index_select(-2, keep0) prune0[:, ind0] += 1 """desc1执行上述同样操作...""" -
scores, _ = self.log_assignment[i](desc0, desc1) m0, m1, mscores0, mscores1 = filter_matches(scores, self.conf.filter_threshold)
接下来对上述步骤分别进行介绍。
特征点归一化
首先对特征点的坐标进行归一化,归一化的目的是与图像分辨率解耦,同时在训练的时候[0,1]的数值和权重值相当,训练会更加稳定。图像坐标系原点位于左上角,即像素坐标范围为,为图像宽,为图像高。归一化后的坐标系原点位于图像的正中心,像素点坐标变换为:
对应的处理函数为:
def normalize_keypoints(
kpts: torch.Tensor, size: Optional[torch.Tensor] = None
) -> torch.Tensor:
if size is None:
size = 1 + kpts.max(-2).values - kpts.min(-2).values
elif not isinstance(size, torch.Tensor):
size = torch.tensor(size, device=kpts.device, dtype=kpts.dtype)
size = size.to(kpts)
shift = size / 2
scale = size.max(-1).values / 2
kpts = (kpts - shift[..., None, :]) / scale[..., None, None]
return kptsTransformer主干网络
传统的特征匹配是围绕特征点的位置和视觉描述子。真正匹配的时候,还有其他可参考的方面,比如特征点之间的相对位置关系。比如我们人类肉眼去匹配两幅图片,就像玩“找不同”游戏一样,会来回查看两张照片,找到图片一个显眼点(特征点)后会在图片去寻找对应的显眼点,然后会很自然的在图显眼点周围再其他显眼点,然后去里面再去找有没有对应点。这样一来一往排查错误匹配的可能性。同时,人类还会找一些全局信息,额外的一些关联信息,来辅助判断,比如匹配时需维持同一物体上特征点的相对关系。LightGlue基于Transformer的注意力机制模拟人进行特征匹配。
LightGlue总共有层网络,每个注意力层采用多头注意力机制,用了4头注意力。状态的维度设置为。
自注意力
代码中自注意力状态计算代码为:
desc0 = self.self_attn(desc0, encoding0)
desc1 = self.self_attn(desc1, encoding1)其中
encoding为位置编码,预先计算完成。因为位置编码结果对所有层都一样,只需要执行一次,不需要在每层网络中都执行。位置编码计算代码为:def forward(self, x: torch.Tensor) -> torch.Tensor: """encode position vector""" """x.shape: [1, 512, 2], projected.shape: [1, 512, 32]""" projected = self.Wr(x) """sines.shape: [1, 512, 32]""" cosines, sines = torch.cos(projected), torch.sin(projected) """emb.shape: [2, 1, 1, 512, 32]""" emb = torch.stack([cosines, sines], 0).unsqueeze(-3) """最终返回值shape: [2, 1, 1, 512, 64]""" return emb.repeat_interleave(2, dim=-1)其中
self.Wr为nn.Linear实例,bias设置为false,输入特征维度为2,输出特征维度为32,用来构建位置旋转编码。需要注意的是,这里用到了4头网络,所以这里的。
self.self_attn为SelfBlock类的实例,该类的forward函数计算过程是:
-
对图像中的特征点,将其当前状态通过不同的线形变换生成key和query向量和。
"""输入x.shape: [1, 512, 256], 512为特征点数,256为特征描述维度,qkv.shape: [1, 512, 768] """ qkv = self.Wqkv(x) """qkv.shape: [1, 4, 512, 64, 3]""" qkv = qkv.unflatten(-1, (self.num_heads, -1, 3)).transpose(1, 2) """q.shape: [1, 4, 512, 64]""" q, k, v = qkv[..., 0], qkv[..., 1], qkv[..., 2]其中
Wqkv(x)为:self.Wqkv = nn.Linear(embed_dim, 3 * embed_dim, bias=bias) -
同一张图像中特征点和特征点之间的自注意力分数定义为:
其中,为相对位置旋转编码:
基于Scaled dot product attention将注意力计算为:
进一步,通过对所有状态加权平均,得到消息如下:
对于自注意力,这里为同一张图像。
对应的代码实现为:
q = apply_cached_rotary_emb(encoding, q) k = apply_cached_rotary_emb(encoding, k) context = self.inner_attn(q, k, v, mask=mask) message = self.out_proj(context.transpose(1, 2).flatten(start_dim=-2)) -
最后更新当前状态:
其中将当前状态和消息连接,并送往MLP层网络。MLP包含一个1D隐藏层,一个Layernorm层,一个GELU层和一个1D卷积网络。实现代码为:
return x + self.ffn(torch.cat([x, message], -1))其中
self.ffn为MLP层,代码实现为:self.ffn = nn.Sequential( nn.Linear(2 * embed_dim, 2 * embed_dim), nn.LayerNorm(2 * embed_dim, elementwise_affine=True), nn.GELU(), nn.Linear(2 * embed_dim, embed_dim)
交叉注意力
计算完两张图像的自注意力状态后,作为交叉注意力单元的输入,计算交叉注意力状态,实现代码为:
desc0 = self.self_attn(desc0, encoding0, mask0)
desc1 = self.self_attn(desc1, encoding1, mask1)
return self.cross_attn(desc0, desc1, mask)图像中的每一个点都和图像的所有点有潜在关系。这里对每个点只计算,对应的,交叉注意力分数定义为:
这样两张图像只需要交叉一次,不需要算完后还需要算,从而节省了算力。在两张图像之间,不需要位置编码,因为相对位置关系没有意义。
除此之外,状态更新和自注意力一样,分别更新两张图的特征点状态,代码如下:
x0 = x0 + self.ffn(torch.cat([x0, m0], -1))
x1 = x1 + self.ffn(torch.cat([x1, m1], -1))
return x0, x1深度动态调整
为了减少不必要的计算和减少推理时间,根据输入图像进行网络深度的动态调整。假如输入图像对很容易匹配上,那么前序网络层预测的token置信度很高,与后续网络层并没有差异,这时可以提前结束推理。
在每一层网络之后,LightGlue都会计算出每个特征点的token置信度:
Token置信度越高,则表明对特征点的表征是越可靠的,更容易被分类成可被匹配的或不可被匹配的。论文中提到多加一层MLP,最坏情况会增加2%的推理时间,但是通常情况下会减少计算量。对应的模型代码为:
self.token = nn.Sequential(nn.Linear(dim, 1), nn.Sigmoid())对于给定网络层,某个特征点是高置信度的,仅当。在头几层网络里,置信度往往都不太高,所以一开始都比较大,后面慢慢变小。阈值随着网络层数变化如下所示:
当如下条件满足时,会提前结束网络层推理:
实际设置。对应深度动态调整代码如下:
confidences = torch.cat([confidences0, confidences1], -1)
threshold = self.confidence_thresholds[layer_index]
ratio_confident = 1.0 - (confidences < threshold).float().sum() / num_points
return ratio_confident > self.conf.depth_confidence宽度动态调整
同样的,为了节省计算量,当推理过程不会提前退出时,一些特征点也会被提前裁剪。对每一个特征点,计算对应的匹配分数,表征特征点有一个对应匹配点的可能性,即匹配度分数:
比如一个点由于遮挡不会在另外一张图像中被检测到,则对应的。
对应的模型代码为:
def get_matchability(self, desc: torch.Tensor):
return torch.sigmoid(self.matchability(desc)).squeeze(-1)其中self.matchability = nn.Linear(dim, 1, bias=True)。
对应的宽度动态调整代码如下:
scores0 = self.log_assignment[i].get_matchability(desc0)
prunemask0 = self.get_pruning_mask(token0, scores0, i)
keep0 = torch.where(prunemask0)[1]
ind0 = ind0.index_select(1, keep0)
desc0 = desc0.index_select(1, keep0)
encoding0 = encoding0.index_select(-2, keep0)
prune0[:, ind0] += 1需要注意的是token置信度和匹配度分数的差异,一句话描述就是:只会对token置信度高的点进行匹配,匹配的质量用匹配度分数表示。因此,一个特征点被认为是unmatchable仅当其token置信度高但是匹配度分数低:
需要将这类unmatchable的特征点裁剪,其中函数
get_pruning_mask定义为:def get_pruning_mask( self, confidences: torch.Tensor, scores: torch.Tensor, layer_index: int ) -> torch.Tensor: """标记将要去除的特征点""" keep = scores > (1 - self.conf.width_confidence) if confidences is not None: # 但是保留低置信度特征点 keep |= confidences <= self.confidence_thresholds[layer_index] return keep
预测匹配矩阵
首先计算点对相似度矩阵如下:
其中为带偏置的线形变换。相似度可认为是这一对点由同一个3D点投影而来的可能性。
最终的分配矩阵(soft partial assignment matrix) 可计算为:
考虑了对应点的相似度以及匹配度分数,也就是说对于一对点,当两个点都是可匹配的且之间的相似度比其他点高,则这一对点是关联点。当的值大于阈值且大于其所在列和行的其他值,那么这一对点确认为匹配点。
对应的执行代码为:
"""计算匹配矩阵"""
scores, _ = self.log_assignment[i](desc0, desc1)
"""得到最高分匹配对,形成最终结果"""
m0, m1, mscores0, mscores1 = filter_matches(scores, self.conf.filter_threshold)其中
self.log_assignment定义如下,每层layer后都有对应的MatchAssignment:self.log_assignment = nn.ModuleList([MatchAssignment(d) for _ in range(n)])
MatchAssignment定义和注释如下:class MatchAssignment(nn.Module): def __init__(self, dim: int) -> None: super().__init__() self.dim = dim self.matchability = nn.Linear(dim, 1, bias=True) self.final_proj = nn.Linear(dim, dim, bias=True) def forward(self, desc0: torch.Tensor, desc1: torch.Tensor): """build assignment matrix from descriptors""" """带偏置的线形变换操作""" mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1) _, _, d = mdesc0.shape mdesc0, mdesc1 = mdesc0 / d**0.25, mdesc1 / d**0.25 """计算点对相似度""" sim = torch.einsum("bmd,bnd->bmn", mdesc0, mdesc1) z0 = self.matchability(desc0) z1 = self.matchability(desc1) scores = sigmoid_log_double_softmax(sim, z0, z1) return scores, sim def get_matchability(self, desc: torch.Tensor): return torch.sigmoid(self.matchability(desc)).squeeze(-1)这里为了节省计算量,将分配矩阵的乘法运算由log变换成加法运算
sigmoid_log_double_softmax。
结语
这里不贴论文的实验结果了,大家自行查看论文。按照作者的话来说,LightGlue从性能和效率来说都完胜SuperGlue。
既然这个大杀器连通训练代码都开源了,工程佬要玩的就是怎么在端侧部署,毕竟Transformer架构对算力的要求很高。另外,就是怎么去实际运行场景采数训练了,毕竟corner case还是挺多。
期待这项技术能更多落地到SfM/SLAM/Robotics领域中,再推一把行业产品体验的提升。
拓展阅读:
[1] 笔记:SuperGlue:Learning Feature Matching with Graph Neural Networks论文阅读
[2] YOUTUBE:LightGlue直播讲解录像-hupo
[3] LightGlue训练代码
[4] ONNX-compatible LightGlue: Local Feature Matching at Light Speed. Supports TensorRT, OpenVINO